Whether you supply education articles to the engineering industry or tips on dog grooming, a proper understanding of Amazon Web Services architecture helps you understand how to better scale up processing capabilities. In this article, you will learn the fundamentals of the AWS data center design, instance design and deployment, and how load balancing occurs.
The Data Centers
Major data centers are clusters of servers located in a region. Each region has availability zones (AZ) inside of that region. Data Centers for AWS are scattered throughout the world, strategically located to meet client service demands.
Each region provides computing power through a framework called EC2. EC2, which stands for elastic compute cloud, allows users to rent virtual computers on which to run various applications.
EC2 – What Is In An Instance?
All EC2 computers are not created equal. To best match computing power to the application, servers are characterized according to their capabilities.
Machines are characterized by five different groups: general-purpose, compute-optimized, memory-optimized, accelerated computing, and storage optimized. These uses are as follows:
- General Purpose (A, T, and M Type) – These computers provide a balance of computing, memory and networking resources, and for a variety of diverse workloads.
- Compute Optimized (C type)- These instances are good fits for high-performance processors, modelling, and machine learning applications.
- Memory Optimized (R and X type) – Memory-optimized machines are fits for workloads that process large data sets at one time.
- Accelerated Optimized (P and G type) – Accelerated optimized are for specific use cases such as graphics processing.
- Storage Optimized (I, D, and H type) – Storage optimized are optimized for workloads that require read and write access to very large data sets on local storage.
Launch Types
The type of launch required depends on the workload required. Instances can be on-demand, reserved, spot, or dedicated. The following use cases apply:
- On-Demand Instances – On-demand instances are applicable where there is a short workload. On-demand offers predictable pricing and is an easy way to begin computing work.
- Reserved Instances – reserved instances require a minimum of a 1-year commitment. Reserved instances can be convertible which are long workloads that allow you to change the type (ex: m4.large next week that ends up being t5.large in 3 months). A scheduled reserve instance runs at a specific time period – for instance, every Saturday for 12 hours when processing large data is required.
- Spot Instances – Spot instances are particularly useful in situations where computational data is required. It allows the user to place a bid on the computing power and allows for up to a 90% discount over on-demand prices. Spot instances are suited to batch jobs, data analysis, and image processing. They are not good fits for critical jobs or databases.
- Dedicated Instances – These instances ensure that no other customers share your hardware. Full control over instance placement is guaranteed as well as visibility into physical cores of the hardware. This type of instance is the most expensive. It sees usefulness for software applications that have a complicated licensing model or is subject to regulatory needs.
Scaling And Load Balancing
In most enterprise applications, a single instance does not meet the needs of the desired application. Thus, additional servers must be spooled up. Rather than creating multiple static instances, a better way may be to dynamically change server capacity. There are two ways to accomplish this: horizontal scaling and vertical scaling.
Vertical Scaling
Vertical scaling is increasing the computing strength of an instance. For example, if your application runs on an m2.micro, vertically scaling that application means you could run it on an m2.large. Vertical scalability is very common for database type of solutions where capacity expands on a somewhat uniform rate. Vertical scalability has limits, usually dictated by the size of the hardware.
Horizontal Scaling
Horizontal scaling increases the number of instances to support operations. Its highly common for web/native applications and can be done easily to meet demand. High availability goes well with horizontal scaling as is the intentional spooling up of servers in other regions to meet demand and reduce risk of a data loss.
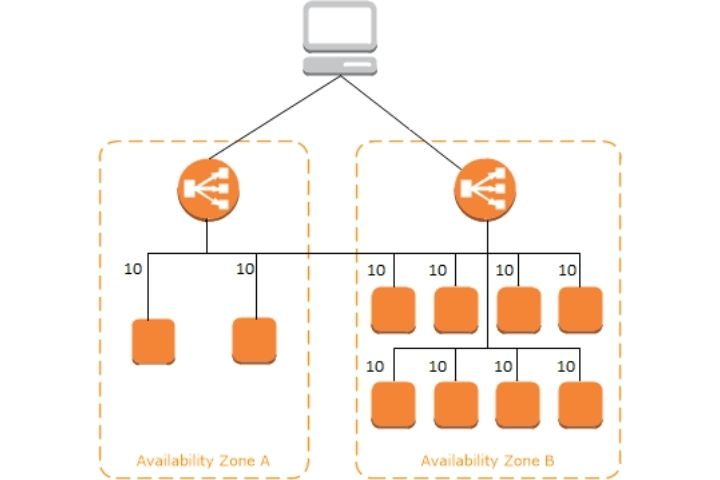
Elastic Load Balancing
Load Balancers are the magic behind the scaling up of EC2 instances. The Elastic Load Balancer is a server that forwards traffic to multiple EC2 instances based on demand. It also performs a health check on the instance and ensures that the instance is able to accept traffic. If the response is not “OK” traffic is directed elsewhere. This allows an additional safeguard to the load balancer. There are three types of elastic load balancers: classic load balancer, application load balancer, and the network load balancer.
The Classic Load Balancer
The classic load balancer originated in 2009 and supports HTTP, HTTPS, and TCP protocols. It is no longer recommended for use as the application load balancer and the network load balancer provide more features.
Application Load Balancer
The application load balancer (ALB) supports HTTP, HTTPS, and WebSocket. ALB is a great fit for microservices and container-based applications such as Docker and Amazon ECS. They have a fixed hostname and uses a private IP into the EC2 instance.
Network Load Balancer
The network load balancer (NLB) supports TCP, TLS (secure TCP) and UDP. They operate at lower latency than the application load balancer. The primary use case is around extreme performance or around TCP and UCP traffic.
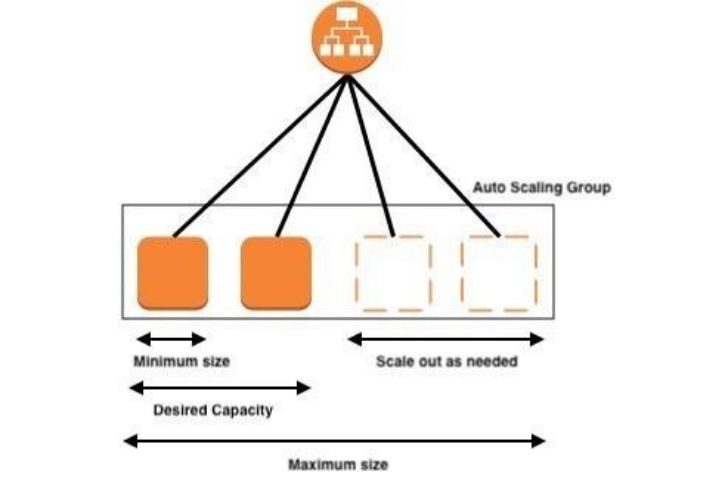
Auto Scaling Group
In real-life applications, user load scales up and down dramatically. Thus, the need arises for servers to be added and removed quickly. An auto-scaling group scales by adding or removing EC2 instances to match the required load. It dictates the minimum and maximum instances that can be assigned.
Application
Where you are a dedicated software engineer or a business development manager, a basic understanding of AWS principles helps your organization understand potential costs and benefits of various infrastructure. Understanding AWS gives you a fundamental understanding of cloud architecture, no matter what cloud provider you may choose.







![TamilRockers Proxy 11 Mirror-Sites [Updated 2022] & How to Unblock It](https://www.techsplashers.com/wp-content/uploads/2022/01/TamilRockers-Proxy-11-Mirror-Sites-Updated-2022-How-to-Unblock-It.jpg)
Leave a Reply